
Quando a OpenAI revelou sua rede neural de criação de imagens DALL-E no início de 2021, a capacidade humana do programa de combinar diferentes conceitos de novas maneiras foi impressionante. A série de imagens que DALL-E gerou era surreal e parecida com desenhos animados, mas mostrava que a IA havia aprendido lições importantes sobre como o mundo funciona. As poltronas de abacate de DALL-E tinham as características básicas de abacates e cadeiras, enquanto que seus nabos passeadores de cachorros vestiam tutus na cintura e seguravam as guias dos cães nas mãos.
Em abril, o laboratório de São Francisco, nos Estados Unidos, anunciou o sucessor do DALL-E, DALL-E 2. Ele produz imagens muito melhores, é mais fácil de usar e, ao contrário da versão original, será disponibilizado ao público (eventualmente). DALL-E 2 pode até mesmo ampliar as definições atuais de Inteligência Artificial (IA), forçando-nos a examinar esse conceito e decidir o que ele realmente significa.
“O salto de DALL-E para DALL-E 2 é uma reminiscência do GPT-2 para GPT-3”, diz Oren Etzioni, CEO do Allen Institute for Artificial Intelligence (AI2) em Seattle, nos Estados Unidos. O GPT-3 também foi desenvolvido pela OpenAI.

“Ursos de pelúcia como cientistas malucos retrofuturistas misturando produtos químicos espumantes ” / “Uma fotografia de filme macro de 35 mm de uma grande família de ratos usando chapéus aconchegantes ao lado de uma lareira”
Modelos de geração de imagem como o DALL-E percorreram um longo caminho em apenas alguns anos. Em 2020, o AI2 apresentou uma rede neural que poderia gerar imagens a partir de prompts como “Três pessoas jogam videogame em um sofá”. Os resultados eram distorcidos e embaçados, mas quase reconhecíveis. No ano passado, a gigante chinesa de tecnologia Baidu melhorou a qualidade das imagens do DALL-E original com um modelo chamado ERNIE-ViLG.
DALL-E 2 leva essa técnica ainda mais longe. Suas criações são impressionantes: ele pode ser solicitado para gerar imagens de astronautas em cavalos, ursinhos de pelúcia cientistas ou lontras marinhas no estilo de Vermeer, e ele o faz com quase fotorrealismo. Os exemplos que a OpenAI disponibilizou (veja abaixo), assim como aqueles que vi em uma demonstração que a empresa me deu em abril, foram escolhidos a dedo. Ainda assim, a qualidade é muitas vezes surpreendente.
“Uma maneira de pensar sobre essa rede neural é a beleza transcendente como serviço”, diz Ilya Sutskever, cofundadora e cientista-chefe da OpenAI. “De vez em quando, ela gera algo que me faz suspirar”.
A melhoria de desempenho do DALL-E 2 deve-se a um redesenho completo. A versão original era mais ou menos uma extensão do GPT-3. De muitas maneiras, o GPT-3 é como um preenchimento automático otimizado: você fornece palavras ou frases e ele continua sozinho, prevendo as próximas centenas de palavras na sequência. DALL-E funcionava da mesma forma, mas em vez de palavras, usava pixels. Quando recebia um prompt de texto, ele “completava” esse texto prevendo a sequência de pixels que provavelmente viria a seguir, produzindo uma imagem.
DALL-E 2 não é baseado em GPT-3. Seu funcionamento interno ocorre em duas etapas. Primeiro, ele usa o modelo de linguagem CLIP da OpenAI, que pode emparelhar descrições escritas com imagens, para traduzir o prompt de texto em uma forma intermediária que identifica as principais características que uma imagem deve ter para corresponder a esse prompt (de acordo com o CLIP). Em segundo lugar, o DALL-E 2 executa um tipo de rede neural conhecido como modelo de difusão para gerar uma imagem de acordo com o CLIP.
Os modelos de difusão são treinados em imagens que foram completamente distorcidas com pixels aleatórios. Eles aprendem a converter essas imagens de volta à sua forma original. No DALL-E 2, não há imagens existentes. Assim, o modelo de difusão pega os pixels aleatórios e, guiado pelo CLIP, os converte em uma imagem totalmente nova, criada do zero, que corresponde ao prompt de texto.
O modelo de difusão permite que o DALL-E 2 produza imagens de alta resolução mais rapidamente do que o DALL-E. “Isso o torna muito mais prático e fácil de usar”, diz Aditya Ramesh da OpenAI.
Na demonstração, Ramesh e seus colegas me mostraram fotos de um ouriço usando uma calculadora, um corgi e um panda jogando xadrez e um gato vestido de Napoleão segurando um pedaço de queijo. Comento sobre o estranho elenco de resultados. “É fácil passar um dia inteiro de trabalho pensando em prompts”, diz ele.

“Uma lontra-marinha no estilo de Moça com o Brinco de Pérola por Johannes Vermeer” / “Um pássaro íbis na natureza, pintado no estilo de John Audubon”
DALL-E 2 de vez em quando erra. Por exemplo, ele pode ter problemas com um prompt que pede para combinar dois ou mais objetos com dois ou mais atributos, como “Um cubo vermelho em cima de um cubo azul”. O OpenAI pensa que isso ocorre porque o CLIP nem sempre conecta os atributos aos objetos corretamente.
Além de reproduzir prompts de texto, o DALL-E 2 pode gerar variações de imagens existentes. Para provar isso, Ramesh insere no sistema uma foto que tirou do lado de fora de seu apartamento de uma arte de rua. A IA imediatamente começa a gerar versões alternativas da cena com diferentes artes na parede. Cada uma dessas novas imagens pode ser usada para iniciar sua própria sequência de variações. “Esse ciclo de feedback pode ser muito útil para designers”, diz Ramesh.
Uma das primeiras usuárias, uma artista chamada Holly Herndon, diz que está usando o DALL-E 2 para criar composições do tamanho de paredes. “Posso juntar obras de arte gigantes, peça por peça, como uma tapeçaria de retalhos ou uma jornada narrativa”, diz ela. “É como trabalhar em um novo meio”.
Atenção aos usuários
DALL-E 2 é um produto muito mais refinado do que a sua versão anterior. Esse não era o objetivo, diz Ramesh. Mas a OpenAI planeja lançar o DALL-E 2 ao público após um lançamento inicial para um pequeno grupo de usuários confiáveis, assim como fez com o GPT-3. (Você pode se inscrever para acessar aqui.)
O GPT-3 pode produzir texto tóxico. Mas a OpenAI diz que usou o feedback que recebeu dos usuários do GPT-3 para treinar uma versão mais segura, chamada InstructGPT. A empresa espera seguir um caminho semelhante com o DALL-E 2, que também será moldado pelo feedback do usuário. A OpenAI incentivará os usuários beta a enganar a IA para gerar imagens ofensivas ou prejudiciais. Depois que esses problemas forem resolvidos, a OpenAI começará a disponibilizar o DALL-E 2 para um grupo mais amplo de pessoas.
A OpenAI também lançou diretrizes para o uso do DALL-E, que proíbe pedir à IA para gerar imagens ofensivas (violentas ou pornográficas) ou imagens políticas. Para evitar deep fakes, os usuários não poderão pedir ao DALL-E para gerar imagens de pessoas reais.

“Uma tigela de sopa que parece um monstro, tricotada de lã” / “Um shiba inu vestindo uma boina e gola alta preta”
Além da política do usuário, a OpenAI removeu certos tipos de imagem dos dados de treinamento do DALL-E 2, incluindo aquelas que mostram violência gráfica. A OpenAI também diz que pagará a moderadores humanos para revisar todas as imagens geradas em sua plataforma.
“Nosso principal objetivo aqui é obter muito feedback para o sistema antes de começar a compartilhá-lo de forma mais ampla”, diz Prafulla Dhariwal da OpenAI. “Espero que eventualmente esteja disponível, para que os desenvolvedores possam criar aplicativos em cima dele”.
Inteligência Criativa
IAs com várias habilidades que podem ver o mundo e trabalhar com conceitos em diferentes modalidades, como linguagem e visão, são um passo em direção à inteligência de propósito geral. DALL-E 2 é um dos melhores exemplos até agora.
Mas ao mesmo tempo em que Etzioni fica impressionado com as imagens que DALL-E 2 produz, é cauteloso sobre o que isso significa para o progresso geral da IA. “Esse tipo de melhoria não está nos aproximando da inteligência geral artificial”, diz ele. “Já sabemos que as IAs são notavelmente capazes de resolver tarefas limitadas usando deep learning. Mas ainda são os humanos que formulam essas tarefas e dão ao deep learning suas ordens”.
Para Mark Riedl, pesquisador de IA da Georgia Tech em Atlanta (EUA), a criatividade é uma boa maneira de medir a inteligência. Ao contrário do teste de Turing, que exige que uma máquina engane um humano por meio de uma conversa, o teste Lovelace 2.0 de Riedl julga a inteligência de uma máquina de acordo com o quão bem ela responde a pedidos para criar algo, como “Um pinguim em Marte vestindo um traje espacial andando com um cachorro robô ao lado do Papai Noel”.
DALL-E pontua bem neste teste. Mas a inteligência é uma escala móvel. À medida que construímos máquinas cada vez melhores, nossos testes de inteligência precisam se adaptar. Muitos chatbots agora são muito bons em imitar a conversa humana, passando, de forma limitada, no teste de Turing. No entanto, eles ainda são irracionais.
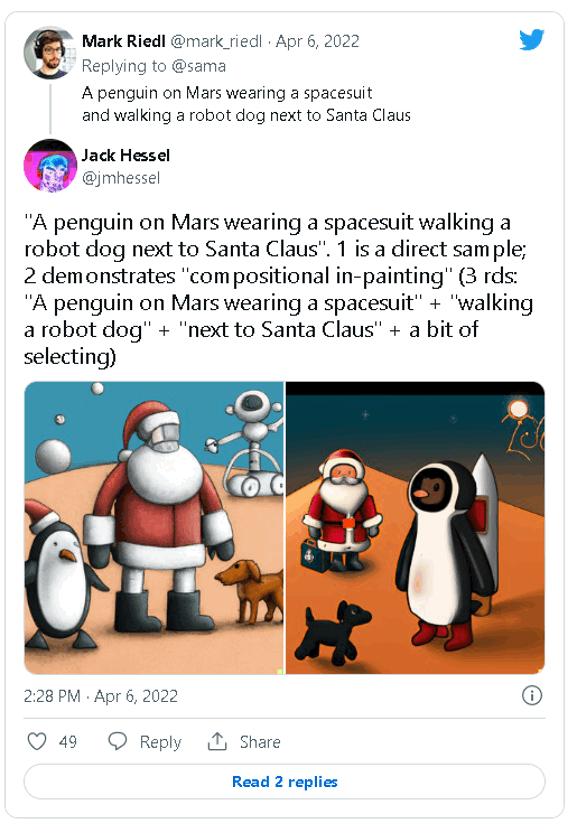
Porém, as ideias sobre o que queremos dizer com “criar” e “entender” também mudam, diz Riedl. “Esses termos são mal definidos e sujeitos a debate.” Uma abelha entende o significado do amarelo porque age sobre essa informação, por exemplo. “Se definirmos compreensão como compreensão humana, então os sistemas de IA ainda tem muito que aprender”, diz Riedl.
“Mas eu também argumentaria que esses sistemas de geração de arte têm algum entendimento básico que combina com entendimento humano”, diz ele. “Eles podem colocar um tutu em um nabo no mesmo lugar que um humano colocaria”.
Assim como a abelha, o DALL-E 2 atua na informação, produzindo imagens que atendem às expectativas humanas. IAs como DALL-E nos levam a pensar sobre essas questões e o que queremos dizer com esses termos.
OpenAI é claro sobre onde está. “Nosso objetivo é criar inteligência geral”, diz Dhariwal. “Construir modelos como o DALL-E 2 que conectam visão e linguagem é um passo crucial em nosso objetivo maior de ensinar as máquinas a perceber o mundo da maneira como os humanos o fazem e, eventualmente, desenvolver a Inteligência Geral Artificial”.

