
Em novembro de 2022, a OpenAI transformou o cenário da Inteligência Artificial ao lançar o ChatGPT, um sistema de chatbot avançado baseado na arquitetura Transformer, que foi introduzida pelo Google em 2017 no influente artigo “Attention is All You Need”. Essa arquitetura revolucionou o campo de processamento de linguagem natural ao introduzir o mecanismo de atenção, permitindo que modelos identificassem relações contextuais complexas entre palavras, resultando em respostas mais coerentes e relevantes.
Atualmente, a plataforma conta com 100 milhões de usuários, e o mercado de IA segue em expansão, com novas formas e aplicações surgindo continuamente. Este artigo tem como objetivo esclarecer o panorama do mercado de IA no cenário pós-ChatGPT, destacando as inovações, as tendências e as oportunidades que surgiram desde o lançamento desse revolucionário sistema.
A popularização dos modelos de linguagem de grande escala (LLM)
O ChatGPT é classificado como um modelo de linguagem de grande escala (LLM, Large Language Models), tecnologia de modelos treinados com vastas quantidades de dados para gerar respostas em linguagem natural. Com a rápida adesão de usuários de diversos perfis, outras grandes empresas também começaram a se posicionar no mercado, levando o setor de LLMs a ganhar forma e expandir rapidamente.
No ano seguinte, em 2023, o Google lançou o Bard, um chatbot baseado em seu próprio modelo que também utiliza a arquitetura Transformer. Subsequentemente, surgiram outros modelos mais avançados, como o Gemini, também do Google, o Claude, da Anthropic, o Ernie, da Baidu, e o Grok, de Elon Musk. Todos esses modelos são proprietários e foram desenvolvidos com o objetivo de conquistar uma parcela do mercado. No entanto, devido às diferenças nas características dos modelos e às diversas demandas do mercado, cada um deles acabou se especializando em diferentes nichos e aplicações.
Por exemplo, o Claude foi desenvolvido com uma forte ênfase em calibrar a ética das respostas, buscando evitar qualquer influência indevida sobre os usuários. O Ernie, por sua vez, foi projetado para operar dentro dos aplicativos chineses, garantindo conformidade com as regulamentações locais e evitando interferências políticas externas. Já o Grok foi integrado ao novo aplicativo de Elon Musk, o X (antigo Twitter), com o objetivo de fornecer respostas e interações diretamente na plataforma.
Iniciativas de Código Aberto
Outro grande player, a Meta (anteriormente conhecida como Facebook), decidiu seguir uma direção oposta ao mercado de IA proprietário, investindo na comunidade com o lançamento do LLaMA (Large Language Model Meta AI), um modelo de código aberto. Reconhecendo os desafios de se reunir uma grande massa de dados de treinamento, como a utilizada no ChatGPT, e o alto custo de processamento para treinar modelos de grande escala, a Meta lançou uma versão específica, o Meta LLaMA 3.1, com uma base pré-treinada e disponível ao público.
Essa abordagem permitiu que desenvolvedores tivessem acesso direto ao código-fonte e pudessem treinar suas próprias versões personalizadas do modelo. A iniciativa fomentou o surgimento de uma série de modelos derivados, incentivando a colaboração e o avanço de tecnologias de IA em ambientes abertos. Com isso, a Meta contribuiu para uma comunidade de desenvolvimento mais inclusiva e inovadora, ampliando o acesso a tecnologias de IA avançadas.
As alternativas de código aberto ganharam força rapidamente. Modelos como o Dolly, desenvolvido pela Databricks, e o Mistral foram introduzidos como opções acessíveis para desenvolvedores que necessitavam de LLMs flexíveis e personalizáveis, sem os altos custos dos modelos fechados e proprietários. Isso permitiu que empresas e pesquisadores desenvolvessem LLMs adaptados às suas necessidades específicas, possibilitando usos mais direcionados e especializados.
Enquanto os modelos proprietários geralmente são projetados para usos genéricos, muitas empresas com expertise em áreas específicas optam por treinar seus próprios modelos para evitar a exposição de dados sensíveis a terceiros, como a OpenAI. O mercado de código aberto, portanto, ganhou adesão dessas empresas, que frequentemente estabelecem seus próprios datacenters de IA e treinam modelos exclusivos para atender às suas demandas de segurança e especialização.
O papel do Fine-Tuning: incorporando conhecimento especializado
Uma das principais inovações na utilização de LLMs é a possibilidade de fine-tuning, ou ajuste fino. Esse processo consiste em utilizar a base já treinada, como o GPT-4 ou o LLaMA 3.1, com dados adicionais específicos para uma aplicação particular. É uma abordagem especialmente vantajosa em contextos que exigem terminologia especializada ou conhecimento profundo, como nas áreas de saúde, direito ou finanças. Com o fine-tuning, o modelo “aprende” padrões e vocabulário específicos de um setor, tornando-se mais preciso e eficiente ao responder perguntas ou realizar tarefas relacionadas àquele domínio.
Empresas e organizações têm demandado muitos serviços de fine-tuning, afirma Gustavo Zaniboni, CAIO da Ananque, “o fine-tuning possibilita treinar modelos de linguagem com dados internos, criando sistemas de IA que compreendem melhor os processos e contextos específicos da instituição”. Esta técnica aumenta significativamente a relevância das respostas e transforma os LLMs em ferramentas práticas e poderosas para uso comercial, ampliando seu valor em aplicações empresariais.
Contexto, Tokens e RAG
Um dos parâmetros que impactam diretamente a qualidade das respostas geradas por modelos de linguagem de grande escala (LLMs) é a janela de contexto, que permite ao modelo reter informações relevantes sobre o assunto discutido ao longo da conversa. Esse contexto atua como uma memória de curto prazo, possibilitando ao LLM uma compreensão mais rica e precisa da consulta. À medida que o contexto aumenta, cresce também o número de tokens (unidades de processamento de linguagem) utilizados, o que demanda mais recursos computacionais e, em consequência, encarece o processamento.
Para as empresas provedoras do serviço mais tokens significa mais lucro, porém, para o usuário, ficava cada vez mais custoso subir um banco de dados especialista em tokens. Tentando unir o melhor para os dois lados começou-se a utilizar uma tecnologia intermediária.
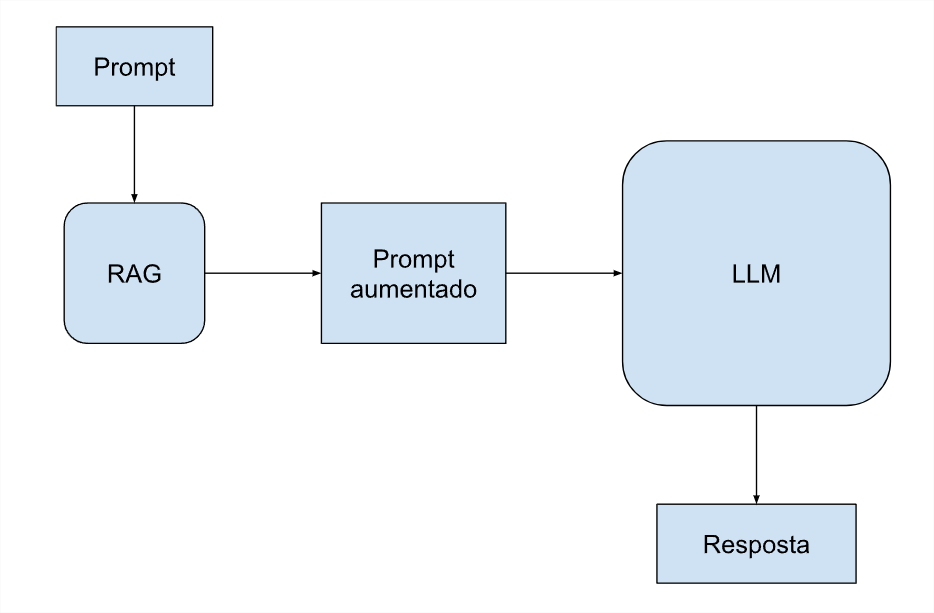
Recuperação de informações com o RAG: reunindo o melhor dos mundos
A tecnologia intermediária serve para a geração aumentada via recuperação de dados, e é chamada em inglês de RAG (Retrieval-Augmented Generation). Ela combina modelos de linguagem com mecanismos de recuperação de informações. A abordagem RAG permite que o modelo acesse e incorpore dados específicos diretamente no prompt, consultando bancos de dados sem a necessidade de enviar todos os tokens a cada solicitação. Essa abordagem otimiza custos, já que reduz o volume de dados processados por consulta, mantendo a precisão e relevância das respostas.
A técnica de RAG também resolve um outro problema, o fato de o LLM ter uma banco de dados pré-treinado e estático, que com o tempo acaba ficando desatualizado. O banco de dados do RAG pode incluir dados externos e manter o conhecimento mais atual e relevante por mais tempo, até que um novo grande treinamento seja realizado.
Importante avaliar que muitos profissionais especializados ainda acreditam que, para pessoa física, ou usuário final, o ChatGPT ainda é o melhor LLM na maioria das tarefas como diz Elisa Terumi, PhD em informática pela PUC-P. “Os modelos proprietários, como os da família GPT-4, geralmente são maiores e mais robustos, treinados em volumes de dados maiores e com um número maior de parâmetros. Também passam por técnicas avançadas de ajuste, como o aprendizado por reforço com feedback humano (RLHF), aprimorando sua capacidade de gerar respostas mais naturais e contextualizadas. Desta forma, modelos da família GPT geralmente apresentam desempenho superior em muitas tarefas.”
No entanto, para uso corporativo, os desafios são distintos, abrangendo aspectos como a sensibilidade dos dados e os altos custos de processamento e de infraestrutura de internet. Essas questões exigem soluções específicas e abordagens estratégicas para garantir segurança, eficiência e viabilidade econômica.
Aplicações corporativas com Small Language Model
Uma empresa que deseja oferecer um serviço especializado com seus próprios dados pode se beneficiar do uso de SLM (Small Language Model). “Essa abordagem está em crescimento no mercado”, afirma Danilo Santos, fundador da Servicedesk Brasil, principalmente impulsionada pela quantidade crescente de especialistas e consultores em IA. Para proteger dados sensíveis e reduzir significativamente os custos de consulta, muitas empresas estão optando por contratar um profissional de IA que instale um LLM em seu próprio data center e o treine do zero.
Geralmente, a base de dados dessas empresas não é tão extensa quanto a utilizada pelas grandes empresas de tecnologia, razão pela qual a técnica é chamada de SLM (Small ao invés de Large). Embora esses modelos envolvam menos dados, eles são capazes de entregar informações relevantes e precisas, mesmo que não tenham a fluidez da linguagem de chat encontrada em LLMs mais robustos, que são projetados para atender a demandas de usuários finais individuais. Essa estratégia permite que as empresas aproveitem suas informações internas de maneira eficaz, enquanto garantem a segurança e a confidencialidade dos dados.
Panorama geral da Inteligência Artificial
A Inteligência Artificial está definitivamente no centro das atenções após o lançamento do ChatGPT. Os LLMs estão gerando um impacto significativo em todos os setores da indústria e serviços. Devido ao seu enorme potencial, investimentos nessa área têm crescido de forma acelerada, resultando em uma constante evolução das tecnologias de IA. Com a crescente adoção dessas soluções por empresas de diversos segmentos, abre-se uma oportunidade sem precedentes para transformar interações, otimizar processos e oferecer soluções mais personalizadas.
Iniciativas de código aberto, como o LLaMA da Meta, juntamente com a implementação de modelos menores, como o SLM, estão democratizando o acesso à IA. Essas abordagens permitem que organizações menores também se beneficiem do poder dos modelos de linguagem, contribuindo para um ecossistema em que inovação e colaboração prosperam. Assim, a Inteligência Artificial se torna cada vez mais acessível e aplicável, estabelecendo-se como um novo e próspero mercado na área de tecnologia da informação.

