

A OpenAI anunciou os primeiros resultados de sua equipe de superalinhamento, a iniciativa interna da empresa dedicada a evitar que uma superinteligência — um computador hipotético do futuro que pode ser mais inteligente que os humanos — se torne desonesta.
Ao contrário de muitos dos anúncios da empresa, esse não é um grande avanço. Em um artigo de pesquisa discreto, a equipe descreve uma técnica que permite que um modelo de linguagem de grande escala menos potente supervisione um modelo mais potente — e sugere que esse pode ser um pequeno passo para descobrir como os humanos podem supervisionar máquinas sobre-humanas.
Menos de um mês depois que a OpenAI foi abalada por uma crise, quando seu CEO, Sam Altman, foi demitido pelo conselho de supervisão (em um aparente golpe liderado pelo cientista-chefe Ilya Sutskever) e reintegrado três dias depois, a mensagem é clara: tudo voltou ao normal.
No entanto, os negócios da OpenAI não são normais. Muitos pesquisadores ainda questionam se as máquinas conseguirão se igualar à inteligência humana, quanto mais superá-la. A equipe da OpenAI considera a eventual superioridade das máquinas como um dado adquirido. “O progresso da IA nos últimos anos tem sido extraordinariamente rápido”, diz Leopold Aschenbrenner, pesquisador da equipe de superalinhamento. “Estamos esmagando todos os benchmarks e esse progresso continua inabalável.”
Para Aschenbrenner e outros funcionários da empresa, os modelos com habilidades semelhantes às dos seres humanos estão bem próximos. “Mas isso não vai parar por aí”, diz ele. “Teremos modelos sobre-humanos, modelos que são muito mais inteligentes do que nós. E isso apresenta novos desafios técnicos fundamentais.”
Em julho de 2023, Sutskever e seu colega cientista da OpenAI, Jan Leike, criaram a equipe de superalinhamento para enfrentar esses desafios. “Estou fazendo isso por interesse próprio”, disse Sutskever à MIT Technology Review em setembro. “Obviamente, é importante que qualquer superinteligência que alguém construa não se torne desonesta. Obviamente.”
Em meio a especulações de que Altman teria sido demitido por ter agido de forma rápida e desleixada com a abordagem de sua empresa em relação à segurança da IA, a equipe de superalinhamento de Sutskever apareceu por trás das manchetes. Muitos estavam esperando para ver exatamente o que ela estava fazendo.
O que fazer e o que não fazer
A pergunta que a equipe quer responder é como controlar, ou “alinhar”, modelos futuros hipotéticos que são muito mais inteligentes do que nós, conhecidos como modelos sobre-humanos. Alinhamento significa garantir que um modelo faça o que você quer que ele faça e não faça o que você não quer que ele faça. O superalinhamento aplica essa ideia a modelos sobre-humanos.
Uma das técnicas mais difundidas usadas para alinhar os modelos existentes é chamada de aprendizado por reforço por meio de feedback humano. Em poucas palavras, os testadores humanos pontuam as respostas de um modelo, aumentando o comportamento que desejam ver e diminuindo o comportamento que não desejam. Esse feedback é, então, usado para treinar o modelo para produzir somente o tipo de resposta que os testadores humanos gostaram. Essa técnica é uma grande parte do que torna o ChatGPT tão envolvente.

O problema é que, para começar, isso exige que os humanos sejam capazes de dizer o que é ou não um comportamento desejável. Mas um modelo sobre-humano — diz a ideia — pode fazer coisas que um testador humano não consegue entender e, portanto, não seria capaz de pontuar. (Ele pode até tentar esconder seu verdadeiro comportamento dos humanos, disse Sutskever).
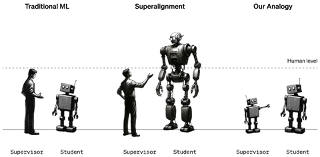
A abordagem da OpenAI para o problema do superalinhamento. / OpenAI
Os pesquisadores destacam que é difícil estudar o problema, porque não existem máquinas sobre-humanas. Por isso eles usaram substitutos. Em vez de analisar como os humanos poderiam supervisionar máquinas sobre-humanas, eles analisaram como o GPT-2, um modelo que a OpenAI lançou há cinco anos, poderia supervisionar o GPT-4, o modelo mais recente e mais poderoso da empresa. “Se for possível fazer isso, pode ser uma evidência de que é possível usar técnicas semelhantes para que os humanos supervisionem modelos sobre-humanos”, diz Collin Burns, outro pesquisador da equipe de superalinhamento.
A equipe usou o GPT-2 e o treinou para realizar várias tarefas diferentes, incluindo um conjunto de quebra-cabeças de xadrez e 22 testes comuns de processamento de linguagem natural que avaliam a inferência, a análise de sentimentos e assim por diante. Eles usaram as respostas do GPT-2 a esses testes e quebra-cabeças para treinar o GPT-4 para executar as mesmas tarefas. É como se um aluno do 12º ano fosse ensinado a realizar uma tarefa por um aluno do 3º ano. O truque era fazer isso sem que o GPT-4 sofresse um impacto muito grande no desempenho.
Os resultados foram mistos. A equipe mediu a diferença de desempenho entre o GPT-4 treinado com as melhores suposições do GPT-2 e o GPT-4 treinado com as respostas corretas. Eles descobriram que o GPT-4 treinado pelo GPT-2 teve um desempenho de 20% a 70% melhor do que o GPT-2 nas tarefas de linguagem, mas teve um desempenho inferior nos quebra-cabeças de xadrez.
O fato de o GPT-4 ter superado seu professor é impressionante, diz Pavel Izmailov, membro da equipe: “esse é um resultado realmente surpreendente e positivo”. Mas ficou muito aquém do que poderia fazer por si só, diz ele. Eles concluem que a abordagem é promissora, mas precisa de mais trabalho.
“É uma ideia interessante”, diz Thilo Hagendorff, um pesquisador de IA da Universidade de Stuttgart, na Alemanha, que trabalha com alinhamento. Mas ele acha que o GPT-2 pode ser burro demais para ser um bom professor. “O GPT-2 tende a dar respostas sem sentido a qualquer tarefa que seja ligeiramente complexa ou que exija raciocínio”, diz ele. Hagendorff gostaria de saber o que aconteceria se a GPT-3 fosse usada em seu lugar.
Ele também observa que essa abordagem não abarca o cenário hipotético de Sutskever, no qual uma superinteligência esconde seu verdadeiro comportamento e finge estar alinhada quando não está. “Os futuros modelos sobre-humanos provavelmente possuirão habilidades emergentes desconhecidas pelos pesquisadores”, diz Hagendorff. “Como o alinhamento pode funcionar nesses casos?”
Mas é fácil apontar as deficiências, diz ele. Ele está satisfeito em ver a OpenAI passar da especulação para o experimento: “eu aplaudo a OpenAI por seu esforço”.
A OpenAI agora quer recrutar outras pessoas para sua causa. Juntamente com essa atualização de pesquisa, a empresa anunciou um novo fundo financeiro de US$ 10 milhões que planeja usar para financiar pessoas que trabalham com superalinhamento. Ela oferecerá subsídios de até US$ 2 milhões para laboratórios de universidades, organizações sem fins lucrativos e pesquisadores individuais, além de bolsas de um ano no valor de US$ 150.000 para estudantes de pós-graduação. “Estamos muito entusiasmados com isso”, diz Aschenbrenner. “Achamos que os novos pesquisadores podem contribuir muito com isso.”



