
Usar técnicas de machine learning tipicamente requer toneladas de exemplos. Para fazer com que um modelo de Inteligência Artificial (IA) reconheça um cavalo, por exemplo, você precisa mostrar a ela milhares de imagens de cavalos. Isso é o que torna a tecnologia computacionalmente cara – e muito diferente do aprendizado humano. Uma criança frequentemente precisa ver apenas alguns exemplos de um objeto, ou até mesmo apenas um, para reconhecê-lo durante toda a vida.
Na verdade, às vezes não precisam de nenhum exemplo para identificar algo. Se mostrar a elas imagens de um cavalo e um rinoceronte, e em seguida dizer que um unicórnio é algo entre os dois, as crianças poderão reconhecer a criatura mística em um livro ilustrado na primeira vez em que a virem.

Hmm… ok, não exatamente. MS TECH / PIXABAY
Agora, um novo artigo científico da Universidade de Waterloo em Ontário, Canadá, sugere que os modelos de IA também deveriam ser capazes de fazer o mesmo — um processo que os pesquisadores chamam de aprendizagem “less than one-shot”, ou LO-shot. Em outras palavras, com essa técnica, um modelo de IA deveria ser capaz de reconhecer de forma precisa mais objetos do que o número de exemplos aos quais foi treinada. Isso pode ser um grande avanço para um campo que está ficando cada vez mais caro e inacessível à medida que os conjuntos de dados usados se tornam cada vez maiores.
Como funciona o aprendizado com “less than one-shot”
Os pesquisadores demonstraram essa ideia pela primeira vez enquanto experimentavam o popular conjunto de dados de visão computacional conhecido como MNIST. O MNIST, que contém 60.000 imagens de treinamento de dígitos manuscritos de 0 a 9, é frequentemente usado para testar novas ideias no campo.
Em um trabalho anterior, os pesquisadores do MIT introduziram uma técnica para “destilar” conjuntos de dados gigantes em minúsculos e, como prova de conceito, eles compactaram o MNIST em apenas 10 imagens. Elas não foram selecionadas do conjunto de dados original, mas cuidadosamente projetadas e otimizadas para conter uma quantidade equivalente de informações ao conjunto completo. Como resultado, quando treinado exclusivamente nas 10 imagens, um modelo de IA pode atingir quase a mesma precisão que um treinado em todas as imagens do MNIST.

Imagens de amostra do conjunto de dados MNIST. WIKIMEDIA

As 10 imagens “destiladas” do MNIST que podem treinar um modelo de IA para atingir 94% de precisão de reconhecimento em dígitos manuscritos. TONGZHOU WANG ET AL
Os pesquisadores de Waterloo queriam levar esse processo de destilação ainda mais longe. Se é possível reduzir 60.000 imagens para 10, por que não as comprimir em cinco? O truque, eles perceberam, era criar imagens que combinassem vários dígitos e, em seguida, alimentá-los em um modelo de IA com rótulos híbridos ou, como são conhecidos, “soft-labels”. (Pense em um cavalo e rinoceronte com características parciais de um unicórnio.)
“Se você pensar no dígito 3, ele também se parece com o dígito 8, mas nada como o dígito 7”, diz Ilia Sucholutsky, estudante de doutorado em Waterloo e principal autora do artigo. “Os soft labels tentam capturar esses recursos compartilhados. Então, em vez de dizer à máquina, ‘Esta imagem é o dígito 3’, dizemos, ‘Esta imagem é 60% o dígito 3, 30% o dígito 8 e 10% o dígito 0’”.
Os limites da aprendizagem LO-shot
Uma vez que os pesquisadores usaram com sucesso soft labels para alcançar o aprendizado LO-shot no MNIST, eles começaram a se perguntar até onde essa ideia poderia realmente ir. Existe um limite para o número de categorias que você pode ensinar a um modelo de IA para identificar a partir de um pequeno número de exemplos?
Surpreendentemente, a resposta parece ser não. Com soft labels cuidadosamente projetadas, mesmo dois exemplos poderiam teoricamente codificar qualquer número de categorias. “Com dois pontos, você pode separar mil, 10.000 ou um milhão de classes”, diz Sucholutsky.
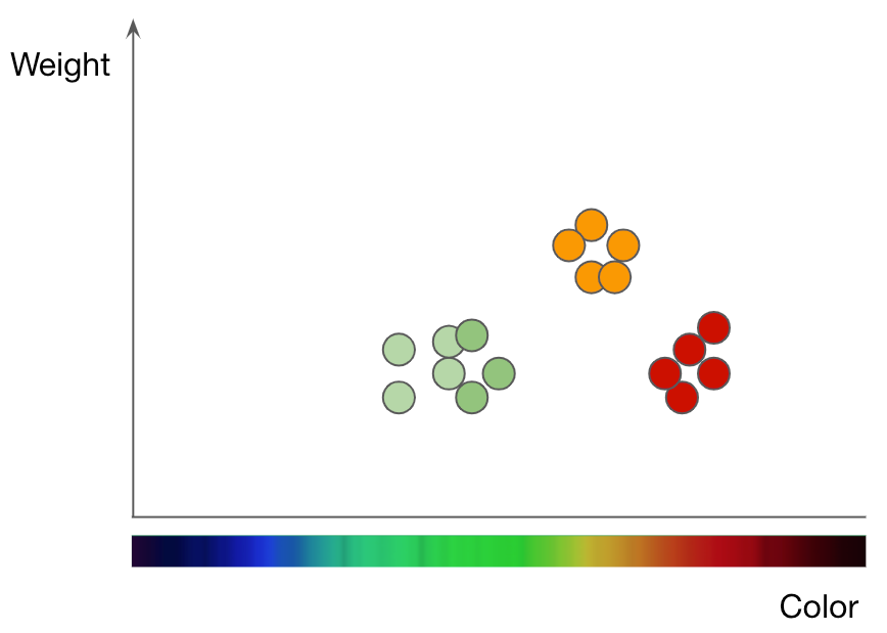
Maçãs de plantio (pontos verdes e vermelhos) e laranjas (pontos laranja) por peso e cor. Adaptação dos slides de Jason Mayes “Machine Learning 101”
É o que os pesquisadores demonstram em seu último artigo, por meio de uma exploração puramente matemática. Eles executam o conceito com um dos algoritmos de machine learning mais simples, conhecido como k-nearest neighbors (kNN, em português pode ser entendido como K-vizinhos mais próximos), que classifica objetos usando uma abordagem gráfica.
Para entender como funciona o kNN, considere a tarefa de classificar frutas como exemplo. Se você deseja treinar um modelo kNN para entender a diferença entre maçãs e laranjas, primeiro você deve selecionar os recursos que deseja usar para representar cada fruta. Talvez você escolha a cor e o peso, então para cada maçã e laranja, você alimenta o kNN um ponto de dados com a cor da fruta como seu valor x e o peso como seu valor y. O algoritmo kNN então agrupa todos os pontos de dados em um gráfico 2D e desenha uma linha divisória entre as maçãs e as laranjas. Neste ponto, o gráfico é dividido nitidamente em duas classes e o algoritmo pode agora decidir se os novos pontos de dados representam um ou outro com base em qual lado da linha eles caem.
Para explorar o aprendizado LO-shot com o algoritmo kNN, os pesquisadores criaram uma série de minúsculos conjuntos de dados sintéticos e projetaram cuidadosamente suas soft labels. Em seguida, eles deixaram o kNN traçar as linhas de limite que estava vendo e descobriram que ele dividiu o gráfico com sucesso em mais classes do que pontos de dados. Os pesquisadores também tinham um alto nível de controle sobre onde as linhas divisórias apareciam. Usando vários ajustes nos soft labels, eles conseguiram que o algoritmo kNN desenhasse padrões precisos na forma de flores.
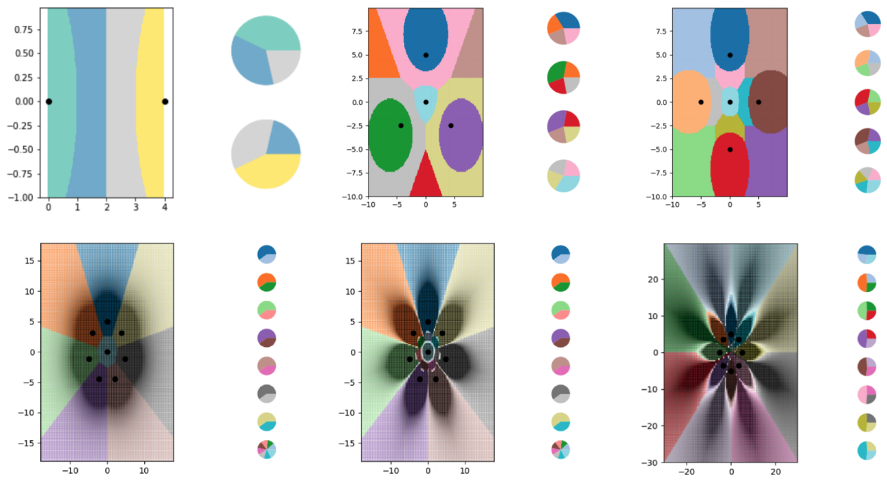
Os pesquisadores usaram exemplos de soft-label para treinar um algoritmo kNN para codificar linhas divisórias cada vez mais complexas, dividindo o gráfico em muito mais classes do que pontos de dados. Cada uma das áreas coloridas nos gráficos representa uma classe diferente, enquanto os gráficos de pizza ao lado de cada gráfico mostram a distribuição do soft label para cada ponto de dados. ILIA SUCHOLUTSKY ET AL
Claro, essas explorações teóricas têm alguns limites. Embora a ideia de aprendizado LO-shot deva ser transferida para algoritmos mais complexos, a tarefa de desenvolver os exemplos de soft-label se torna substancialmente mais difícil. O algoritmo kNN é interpretável e visual, tornando possível para humanos projetar os rótulos; as redes neurais são complicadas e impenetráveis, o que significa que o mesmo pode não ser verdade. A destilação de dados, que funciona para projetar exemplos de soft-label para redes neurais, também tem uma grande desvantagem: exige que você comece com um conjunto de dados gigante para reduzi-lo a algo mais eficiente.
Sucholutsky diz que está trabalhando agora para descobrir outras maneiras de projetar esses minúsculos conjuntos de dados sintéticos – quer isso signifique projetá-los manualmente ou com outro algoritmo. Apesar desses desafios adicionais de pesquisa, no entanto, o artigo fornece os fundamentos teóricos para o aprendizado LO-shot. “A conclusão é que, dependendo do tipo de conjunto de dados que você tem, provavelmente você pode obter ganhos de eficiência massivos”, diz ele.
Isso é o que mais interessa a Tongzhou Wang, um estudante de doutorado do MIT que liderou a pesquisa anterior sobre destilação de dados. “O artigo se baseia em um objetivo realmente novo e importante: aprender modelos poderosos a partir de pequenos conjuntos de dados”, diz ele sobre a contribuição de Sucholutsky.
Ryan Khurana, um pesquisador do Montreal AI Ethics Institute, sente o mesmo: “De forma mais significativa, o aprendizado LO-shot reduziria radicalmente os requisitos de dados para construir um modelo funcional”. Isso poderia tornar a IA mais acessível para empresas e setores que até agora foram prejudicados pelos requisitos de dados do campo. Também poderia melhorar a privacidade dos dados, porque menos informações teriam que ser extraídas dos indivíduos para treinar modelos úteis.
Sucholutsky ressalta que as pesquisas ainda são iniciais, mas ele está animado. Cada vez que ele começa a apresentar seu artigo a outros pesquisadores, a reação inicial deles é dizer que a ideia é impossível, diz ele. Quando de repente eles percebem que não é, isso abre um mundo totalmente novo.



