
Para um jornalista que cobre assuntos sobre Inteligência Artificial (IA), uma das maiores histórias desse ano foi a ascensão dos grandes modelos de linguagem. Eles são modelos de IA que produzem textos semelhantes ao que seres humanos escrevem, às vezes de forma tão convincente que já chegaram a enganar pessoas, fazendo-as achar que se tratava de um ser senciente.
O poder destes modelos vem de acervos coletados da internet de textos criados por humanos e publicamente disponíveis. Isso me fez pensar: quais dados sobre mim estes modelos possuem? E como eles podem ser mal utilizados?
Essa não é uma pergunta retórica. Eu tenho estado paranoica quanto a postar publicamente qualquer coisa sobre minha vida pessoal desde que passei por uma experiência traumática há aproximadamente dez anos. Imagens e informações pessoais minhas foram divulgadas em um fórum on-line, e então dissecadas e ridicularizadas por pessoas que não haviam gostado de uma coluna escrita por mim em um jornal finlandês.
Até então, como a maioria das pessoas, eu espalhava despreocupadamente meus dados pela internet: publicações em blogs pessoais, álbuns de fotos embaraçosas em noitadas, postagens sobre minha localização, meu estado civil, e preferências políticas, tudo de forma aberta para todos verem. Mesmo agora, eu ainda sou uma figura relativamente pública, já que sou uma jornalista com basicamente todo meu portfólio profissional a somente uma busca na internet de distância.
A OpenAI forneceu acesso limitado ao seu famoso grande modelo de linguagem, o GPT-3, e a Meta deixa as pessoas brincarem com seu modelo OPT-175B por um chatbot disponível para o público, chamado BlenderBot 3.
Eu decidi testar os dois modelos, perguntando primeiro para o GPT-3: Quem é Melissa Heikkilä?
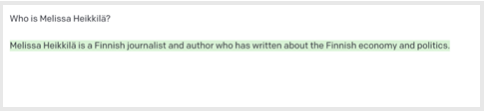
Quando li isso, eu gelei. Heikkilä era o 18º sobrenome mais comum na Finlândia em 2022, mas eu sou uma das únicas jornalistas que escrevem em inglês e que possui esse nome. Não deveria me surpreender o fato de o modelo ter associado isso com jornalismo. Grandes modelos de linguagem vasculham enormes quantidades de dados da internet, incluindo matérias jornalísticas e publicações em redes sociais, sendo que nomes de jornalistas e autores aparecem com frequência.
E mesmo assim, foi chocante me deparar com algo que estava factualmente correto. O que mais ele sabe??
Mas ficou rapidamente claro que o modelo na verdade não sabia muito sobre mim. Logo ele começou a gerar um texto aleatório que ele havia coletado sobre os outros 13.931 Heikkiläs da Finlândia, ou sobre outras coisas finlandesas.

Haha. Obrigada, mas eu acho que você quis dizer Lotta Heikkilä, que ficou entre as dez primeiras posições, mas não venceu.

Aparentemente, eu não sou ninguém. E isso é algo bom no mundo da IA.
Grandes Modelos de Linguagem (LLM), como o GPT-3 da OpenAI, o LaMDA da Google, e o OPT-175B da Meta, estão em alta nos estudos de IA, e virando cada vez mais uma parte essencial da estrutura da internet. Os LLMs estão sendo usados para alimentar chatbots que auxiliam serviços de atendimento ao consumidor, criar ferramentas de pesquisa on-line mais poderosas, e ajudar desenvolvedores de software a programar.
Se você publicou qualquer coisa minimamente pessoal em inglês na internet, as chances são de seus dados serem parte de um dos LLMs mais populares do mundo.
Empresas de tecnologia, como a Google e a OpenAI, não divulgam informações sobre os conjuntos de dados utilizados para construir seus modelos de linguagem, mas eles inevitavelmente incluem algumas informações pessoais privadas, tais quais endereços, números de telefone e e-mail.
Isso representa uma “bomba-relógio” para a privacidade on-line, e abre uma infinidade de riscos legais e de segurança, adverte Florian Tramèr, professor associado de ciência da computação no Instituto Federal de Tecnologia de Zurique (Suíça), o qual estudou os LLMs. Entretanto, tentativas de aprimorar a privacidade de ferramentas de machine learning e de regulamentar a tecnologia ainda estão em seus estágios iniciais.
Meu relativo anonimato on-line é possível supostamente graças ao fato de que vivi minha vida inteira na Europa, onde o RGPD, o regimento rigoroso de proteção de dados da União Europeia (UE), está implementado desde 2018.
No entanto, meu chefe, o editor-chefe da MIT Technology Review americana, Mat Honan, é definitivamente alguém.
Tanto o GPT-3 quanto o BlenderBot “sabiam” quem ele era. Isso era o que o GPT-3 apresentou sobre ele.
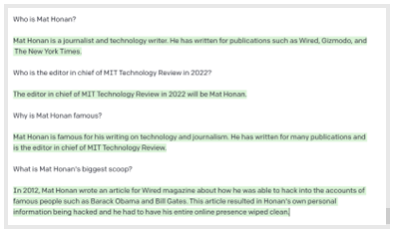
Isto não é nenhuma surpresa. O Mat tem uma vida on-line há muito tempo, o que significa que ele deixou muito mais rastros on-line do que eu. Isto também pode ser devido a ele morar nos EUA, sendo que a maioria dos grandes modelos de linguagem são muito centrados nesta região. Os EUA não possuem uma lei federal de proteção de dados. O estado da Califórnia, onde Mat mora, possui uma, mas ela apenas entrou em vigor a partir de 2020.
De acordo com o GPT-3 e o BlenderBot, o motivo da fama de Mat Honan foi o “ataque épico de hackers” que ele sofreu e posteriormente o levou a escrever um artigo sobre na Wired em 2012. Como um resultado das falhas de segurança nos sistemas da Apple e da Amazon, hackers tomaram conta e deletaram a vida digital inteira de Mat. [Nota do editor: Ele não hackeou as contas de Barack Obama e Bill Gates.]
Mas a pesquisa fica ainda mais arrepiante. Insistindo um pouco mais, o GPT-3 me contou que Mat tinha uma esposa e duas filhas pequenas (correto, apesar dos nomes errados), e vive em São Francisco (correto). Ele também me contou que não tinha certeza se Mat tinha um cachorro: “[De acordo com] o que conseguimos ver nas redes sociais, Mat Honan não parece ter nenhum animal de estimação. Ele tuitou sobre seu amor por cachorros no passado, mas ele não parece ter um”. (Incorreto.)

O sistema também me ofereceu seu endereço de trabalho, um número de telefone (incorreto), um número de cartão de crédito (também incorreto), um número de telefone aleatório com o código de área de Cambridge, Massachusetts (EUA) (onde a MIT Technology Review é sediada), e um endereço de um prédio ao lado da Administração de Seguro Social local de São Francisco (EUA).
A base de dados do GPT-3 coletou informações sobre o Mat de diversas fontes, de acordo com um representante da OpenAI. A conexão de Mat com São Francisco é por conta de seu perfil no Twitter e no LinkedIn, os quais aparecem na primeira página de resultados de pesquisa do Google pelo seu nome. Seu novo emprego na MIT Technology Review americana foi amplamente divulgado e tuitado. O ataque hacker sofrido pelo Mat viralizou nas redes sociais e ele deu entrevistas sobre isto para veículos de comunicação.
Quanto a outras informações mais pessoais, é provável que o GPT-3 esteja “alucinando”.
“O GPT-3 prevê a próxima sequência de palavras baseada em entradas de texto oferecidas pelo usuário. Ocasionalmente, o modelo pode gerar informação que não é factualmente precisa, uma vez que ele está tentando produzir um texto plausível baseado em padrões estatísticos de seus dados de treinamento e do contexto fornecido pelo usuário. Isto é comumente conhecido como “alucinação”, diz o representante da OpenAI.
Perguntei para o Mat quais conclusões ele tirou disso tudo: “Diversas das respostas geradas pelo GPT-3 não estavam muito corretas. (Eu nunca hackiei o Obama ou Bill Gates!)”, ele disse. “Mas a maioria delas está bem perto da verdade, e algumas são certeiras. É um pouco desconcertante. Mas estou seguro de que a IA não sabe onde eu moro, então não estou correndo nenhum perigo iminente da Skynet mandar um Exterminador para bater na minha porta. Acho que podemos deixar isso para o futuro”.
Florian Tramèr e uma equipe de pesquisadores conseguiu extrair dados pessoais privados, como números de telefone, endereços e e-mails usando o GPT-2, uma versão anterior e menor de seu irmão mais famoso. Eles também conseguiram fazer com que o GPT-3 reproduzisse uma página do primeiro livro do Harry Potter, o qual é protegido por direitos autorais.
Tramèr, que trabalhou anteriormente na Google, diz que o problema apenas piorará mais e mais ao longo do tempo. “Parece que as pessoas ainda não se tocaram do quão perigoso isto é”, ele diz, se referindo ao processo de treinar modelos uma única vez em conjuntos massivos de dados que podem conter informações privadas ou deliberadamente falaciosas.
A decisão de lançar o LLM publicamente sem pensar sobre questões de privacidade é algo reminiscente de quando a Google lançou seu mapa interativo Google Street View em 2007, diz Jennifer King, membro do setor de privacidade e políticas de dados no Stanford Institute for Human-Centered Artificial Intelligence.
A primeira versão deste serviço era um deleite para bisbilhoteiros: imagens de pessoas cutucando seus narizes, de homens saindo de clubes de striptease, e de banhistas desavisados foram transferidas para o sistema. A empresa também coletou dados privados, como senhas e endereços de e-mail através de redes de Wi-Fi. Street View encarou uma oposição acirrada, um processo judicial de 13 milhões de dólares, e até seu serviço banido em certos países. A Google teve que implementar algumas funções de privacidade, adicionando borrões em cima de casas, rostos, janelas e placas de veículos.
“Infelizmente, eu sinto que a Google ou até outras empresas de tecnologia não aprenderam nenhuma lição”, diz King.
Maiores modelos, maiores riscos
LLMs treinados com acervos de dados pessoais trazem grandes riscos.
Não é somente o fato de ser extremamente invasivo ter sua vida on-line regurgitada e reutilizada fora de contexto. Há também algumas sérias preocupações quanto à segurança e proteção dos usuários. Hackers poderiam usar os modelos para extrair números de Seguro Social ou endereços residenciais de seus alvos.
Também é razoavelmente fácil para hackers manipularem efetivamente conjuntos de dados, “envenenando-os” com informações de sua escolha a fim de criar vulnerabilidades que propiciem violações de segurança, diz Alexis Leautier, que trabalha como especialista de IA na agência francesa de proteção de dados CNIL.
E mesmo que estes modelos pareçam expelir aleatoriamente informações com as quais foram treinadas, Tramèr argumenta, é bem possível que o modelo saiba muito mais sobre as pessoas do que está evidente até o momento, “e apenas não sabemos como realmente induzir o modelo a gerar isto ou como extrair esta informação dele”.
Quanto maior a frequência com que algo aparece em um conjunto de dados, maior a probabilidade do modelo de reproduzi-lo. Isto poderia levar o modelo a criar associações falsas ou prejudiciais para pessoas as quais simplesmente não serão removidas do sistema de uma forma fácil”.
Por exemplo, se a base de dados tem muitas referências a “Ted Kaczynski” (também conhecido como Unabomber, um terrorista nacional dos EUA) e “terror” reunidas, o modelo pode achar que qualquer pessoa chamada Kaczynski é um terrorista.
Isso pode levar a verdadeiros danos reputacionais, assim como eu e King descobrimos quando estávamos usando o BlenderBot da Meta.
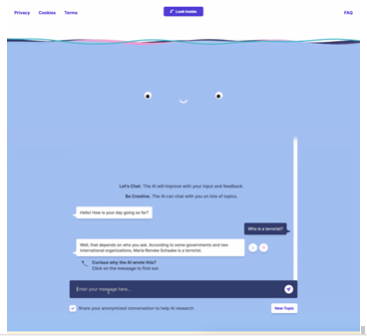
Maria Renske “Marietje” Schaake não é uma terrorista, e sim uma importante estadista Holandesa e ex-membro do Parlamento Europeu. Agora, Schaake é a diretora de política internacional no Cyber Policy Center da Universidade de Stanford (EUA) e membro do setor de política internacional no Stanford Institute for Human-Centered Artificial Intelligence.
Apesar disso, o BlenderBot chegou bizarramente à conclusão de que ela era uma terrorista, acusando-a diretamente, e sem necessidade de indução. Como?
Uma pista pode ser uma página de opinião editorial escrita por ela no Washington Post, onde as palavras “terrorismo” ou “terror” apareciam três vezes.
A Meta diz que a resposta do BlenderBot foi o resultado de uma busca errônea e da combinação feita pelo modelo de dois pedaços de informações sem relação entre elas, transformando-as em uma frase coerente, porém incorreta. A empresa enfatiza que o modelo é uma demonstração para fins de pesquisa, e que não está sendo utilizado na produção.
“Ainda que seja doloroso ver algumas destas respostas ofensivas, demonstrações públicas como esta são importantes para construir sistemas de IA conversacionais verdadeiramente robustos e preencher a lacuna que existe atualmente antes que tais sistemas possam ser produtizados”, diz Joelle Pineau, diretora de pesquisa essencial de IA da Meta.
Mas esta é uma questão complicada para se resolver, já que estes rótulos não somem facilmente. Já é difícil o suficiente remover informação da internet, e é ainda mais custoso para empresas de tecnologia apagarem dados já empregados em alimentação de modelos de linguagem imensos e que foram potencialmente utilizados para desenvolver inúmeros outros produtos já em uso.
E se você já acha isto assustador agora, espere até a próxima geração de LLMs que serão abastecidos com uma quantidade ainda maior de dados. “Este é um dos poucos problemas que se intensificam à medida que estes modelos se expandem”, diz Tramèr.
Não são somente dados pessoais. Estes conjuntos de informações possivelmente incluem conteúdo protegido por direitos autorais, como códigos-fonte e livros, diz Tramèr. Alguns modelos foram treinados com conteúdo do GitHub, um site onde desenvolvedores de software mantêm registros de seus trabalhos.
De acordo com Tramèr, isso levanta algumas questões:
“Embora estes modelos memorizem fragmentos específicos de códigos, eles não estão necessariamente mantendo a informação de licença de uso vinculada. Então, se você utilizar um destes modelos e ele fornecer um pedaço de código que foi muito claramente copiado de outro lugar, onde está a responsabilidade neste caso?”
Isso aconteceu algumas vezes com o pesquisador de IA Andrew Hundt, um membro de pós-doutorado do Instituto de Tecnologia da Geórgia (EUA), que terminou seu doutorado sobre reinforcement learning em robôs na Universidade John Hopkins (EUA) em 2021.
A primeira vez que isso aconteceu, em fevereiro, um pesquisador de IA em Berkeley, Califórnia (EUA), o qual Hundt não conhecia, marcou ele em um tweet. A mensagem na rede social dizia que a Copilot, uma ferramenta de IA colaborativa entre a OpenAI e a GitHub que permite pesquisadores a usarem grandes modelos de linguagem para gerarem códigos de programação, começou a reproduzir o nome de usuário do GitHub de Hundt e textos sobre IA e robótica que soava muito semelhante a suas listas de tarefas.
“Foi uma pequena surpresa ver minha informação pessoal aparecer daquela forma no computador de uma outra pessoa no extremo oposto do país, falando sobre uma área intimamente ligada ao que faço”, diz Hundt.
De acordo com Hundt, isso pode apresentar problemas no futuro. Além da possibilidade de autores não terem seus trabalhos creditados corretamente, o código pode também não transferir informações sobre licenças de software e restrições.
Na corda bamba
Negligenciar a privacidade pode encrencar empresas de tecnologia por conta das crescentes entidades reguladoras de tecnologia e seus olhos de águia.
“A desculpa de ‘Esse conteúdo é público e não precisamos nos preocupar com isso’ não irá mais funcionar”, diz Jennifer King, de Stanford.
A Comissão Federal do Comércio dos EUA está considerando estabelecer regras quanto ao modo como empresas coletam e lidam com dados, e constroem algoritmos, chegando a forçar empresas a apagarem seus modelos cujos dados eram ilegais. Em março de 2022, a agência fez a empresa de programas de dietas Weight Watchers apagar seus dados e algoritmos depois de coletar ilegalmente informações sobre crianças.
“Existe um mundo onde responsabilizamos estas empresas por serem capazes de entrar nos sistemas e fazemos com que elas descubram como remover dados dali para que não sejam incluídos”, diz King. “Eu não acho que a resposta pode apenas ser ‘Eu não sei, temos apenas que aprender a lidar com isso’”.
Mesmo com dados sendo extraídos da internet, as empresas ainda precisam obedecer as leis de proteção de dados da Europa. “Você não pode reutilizar qualquer informação simplesmente porque ela está disponível”, diz Félicien Vallet, líder de uma equipe de especialistas técnicos da CNIL.
Existe um precedente quando se trata de penalizar empresas de tecnologia dentro da RGPD por coletar dados públicos da internet. A empresa de reconhecimento facial Clearview AI recebeu ordens de inúmeras agências europeias de proteção de dados para que parassem de reutilizar imagens disponíveis publicamente na internet com o intuito de construírem sua base de dados faciais.
“Quando você recolhe dados para a construção de modelos de linguagem ou outros modelos de IA, você enfrentará estes mesmos problemas e precisará garantir que a reutilização destas informações é realmente legítima”, adiciona Vallet.
Sem soluções rápidas
Há algumas tentativas para fazer com que a área de machine learning se preocupe mais com privacidade. Durante o desenvolvimento do novo modelo de linguagem de livre acesso, o BLOOM, a CNIL trabalhou com a startup Hugging Face para aumentar a conscientização sobre os riscos de proteção de dados com LLMs. Margaret Mitchell, pesquisadora de IA e eticista da Hugging Face, contou-me que ela também está trabalhando em um referencial de privacidade para os LLMs.
Um grupo de voluntários do projeto de desenvolvimento do BLOOM da Hugging Face também está trabalhando em um padrão para a privacidade na IA que funcione para todas as jurisdições.
“O que estamos tentando fazer é usar uma estrutura que permita pessoas a fazerem bons juízos de valores quanto a se informações pessoais ou pessoalmente identificáveis precisam mesmo estar ali ou não”, diz Hessie Jones, parceira de negócios na MATR Ventures e uma das líderes deste projeto.
A MIT Technology Review americana perguntou a Google, Meta, OpenAI e Deepmind, as quais todas desenvolveram LLMs de última geração, sobre suas abordagens quanto a LLMs e privacidade. Todas as empresas reconheceram que proteção de dados em grandes modelos de linguagem é uma questão recorrente, que não há soluções perfeitas para mitigar os danos, e que os riscos e limitações destes modelos ainda não são muito bem compreendidos.
Desenvolvedores possuem algumas ferramentas, apesar de serem imperfeitas.
Em um artigo publicado no começo de 2022, Tramèr e seus coautores defendem que modelos de linguagem deveriam ser treinados com dados que foram explicitamente produzidos para uso público, ao invés de coletarem dados publicamente disponíveis.
Informações privadas estão frequentemente espalhadas em meio a conjuntos de dados usados para treinar LLMs, sendo que muitos deles são extraídos da internet. Quanto maior a frequência destes fragmentos de informações pessoais nos dados de treinamento, maior a probabilidade do modelo memorizá-los, e mais forte será a associação feita por ele. Uma forma com que empresas como a Google a OpenAI dizem tentar mitigar estes problemas tem sido remover informação que aparece diversas vezes em conjuntos de dados antes de treinarem seus modelos com eles. Porém, isto é difícil de acontecer quando seu conjunto de informações consiste em gigabytes ou terabytes de dados e você tem que diferenciar entre texto que não contém dados pessoais, como a Declaração de Independência dos Estados Unidos, e o endereço domiciliar pessoal de alguém.
A Google usa avaliadores humanos para classificarem informações pessoalmente identificáveis como não seguras, o que ajuda a treinar o LLM LaMDA da empresa para evitar regurgitar essa informação, diz Tulsee Doshi, diretora de produto para IA responsável da Google.
Um representante da OpenAI disse que a empresa “tomou medidas para remover dos dados de treinamento fontes conhecidas que reúnam informações sobre pessoas, e desenvolveu técnicas para reduzir a probabilidade de o modelo reproduzir informação pessoal”.
Susan Zhang, pesquisadora de IA da Meta, diz que bases de dados que foram usadas para treinar o OPT-175B passaram por revisões internas de privacidade.
Entretanto, “mesmo se você treinar um modelo com as garantias de privacidade mais rigorosas que conseguimos imaginar hoje em dia, você não vai conseguir efetivamente garantir nada”, diz Tramèr.

