
Uma modificação em como os neurônios artificiais funcionam em redes neurais pode tornar IAs mais fáceis de decifrar.
Os neurônios artificiais – os blocos fundamentais das redes neurais profundas – sobreviveram quase inalterados por décadas. Embora essas redes deem poder à Inteligência Artificial moderna, elas também são enigmáticas.
Os neurônios artificiais existentes, utilizados em modelos de linguagem como o GPT-4, funcionam recebendo um grande número de inputs, somando-os e convertendo essa soma em um output a partir de outra operação matemática dentro do neurônio. Combinações desses neurônios formam redes neurais, e o seu funcionamento combinado pode ser difícil de decifrar.
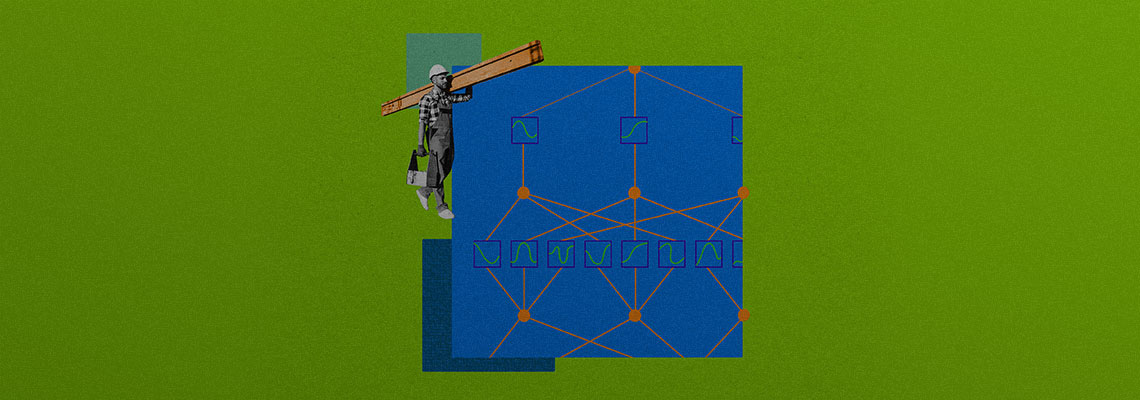
Entretanto, o novo modo de combinar neurônios funciona de maneira um pouco diferente. Parte da complexidade dos neurônios existentes é tanto simplificada quanto movida para fora deles. Dentro dos novos neurônios, basta somar os inputs e produzir um output, sem a necessidade de uma operação secreta a mais. As redes de tais neurônios são chamadas de Redes Kolmogorov-Arnold (KANs), em homenagem aos matemáticos russos que as inspiraram.
A simplificação, estudada detalhadamente por um grupo liderado por pesquisadores do MIT, pode facilitar o entendimento de por que as redes neurais produzem certos resultados, ajudar a verificar suas decisões e até mesmo investigar possíveis vieses. Evidências preliminares também sugerem que, à medida que as KANs crescem, sua precisão aumenta mais rapidamente do que as redes construídas com neurônios tradicionais.
“É um trabalho interessante”, diz Andrew Wilson, que estuda os fundamentos do Machine Learning na Universidade de Nova York. “É bom ver que as pessoas estão tentando repensar fundamentalmente o design dessas [redes].”
Os elementos básicos das KANs foram propostos, na verdade, nos anos 1990, e os pesquisadores continuaram construindo versões simples dessas redes. Contudo, a equipe liderada pelo MIT levou a ideia adiante. Ela mostrou como construir e treinar KANs maiores, realizou testes empíricos nelas e analisou algumas para demonstrar como sua capacidade de resolver problemas poderia ser interpretada por humanos. “Revitalizamos essa ideia”, disse Ziming Liu, membro do time e doutorando no laboratório de Max Tegmark no MIT. “E esperamos que, com a interpretabilidade… [talvez] não pensemos [obrigatoriamente] que redes neurais são caixas-pretas.”
Embora ainda seja cedo, o trabalho da equipe sobre as KANs está atraindo atenção. Páginas no GitHub surgiram mostrando como usá-las para diversas aplicações, como reconhecimento de imagens e resolução de problemas na dinâmica de fluidos.

Encontrando a fórmula
O avanço atual veio quando Liu e seus colegas do MIT, Caltech e outros institutos tentavam entender o funcionamento interno do modelo-padrão das redes neurais artificiais.
Hoje, quase todos os tipos de IA, incluindo aqueles usados para construir grandes modelos de linguagem e sistemas de reconhecimento de imagens, incluem sub-redes conhecidas como perceptron multicamada (MLP). Nele, os neurônios artificiais são organizados em “camadas” densamente interconectadas, e cada um possui internamente algo chamado de “função de ativação” – uma operação matemática que recebe vários inputs e os transforma de uma maneira pré-especificada em um output.
Em um MLP, cada neurônio artificial recebe inputs de todos os neurônios na camada anterior e os multiplica por um “peso” correspondente (um número que indica sua importância). Esses inputs, agora com “pesos”, são somados e alimentados na função de ativação dentro do neurônio para gerar um output, que, então, é passado para os neurônios na camada seguinte. Um MLP aprende a distinguir entre imagens de gatos e cães, por exemplo, escolhendo os valores corretos para os “pesos” dos inputs de todos os neurônios. Crucialmente, a função de ativação é fixa e não muda durante o treinamento.
Uma vez treinados, todos os neurônios de um MLP e suas conexões, tomados em conjunto, agem essencialmente como outra função que recebe um input (digamos, dezenas de milhares de pixels em uma imagem) e produz o output desejado (digamos, “0” para gato e “1” para cachorro). Entender como essa função se parece, ou seja, sua forma matemática, é uma parte importante para ser capaz de entender por que ela produz certos resultados. Por exemplo, por que ele classifica alguém como “financeiramente confiável” com base em inputs sobre seu status financeiro? Por outro lado, os MLPs são caixas-pretas. Fazer engenharia reversa na rede é praticamente impossível em tarefas complexas, como o reconhecimento de imagens.
E mesmo quando Liu e seus colegas tentaram fazer engenharia reversa em um MLP para tarefas mais simples, que envolviam dados “sintéticos” personalizados, eles tiveram dificuldades.
“Se não conseguirmos nem mesmo interpretar esses conjuntos de dados sintéticos a partir das redes neurais, então é impossível lidar com conjuntos de dados do mundo real”, diz Liu. “Achamos muito difícil tentar entender essas redes neurais. Queríamos mudar a arquitetura.”
Mapeando a Matemática
A principal mudança foi remover a função de ativação fixa e introduzir uma muito mais simples e compreensível para transformar cada input antes que ele entre no neurônio.
Ao contrário da função de ativação em um neurônio MLP, que recebe inúmeros inputs, cada função simples fora do neurônio KAN recebe um número e responde outro. Agora, durante o treinamento, em vez de aprender os “pesos” individuais, como acontece em um MLP, a KAN simplesmente aprende como representar cada função simples. Em um artigo publicado este ano no servidor de pré-prints ArXiv, Liu e seus colegas mostraram que essas funções simples fora dos neurônios são muito mais fáceis de interpretar, viabilizando a reconstrução da forma matemática da função que a KAN inteira está aprendendo.
No entanto, a equipe só testou a interpretabilidade das KANs em conjuntos de dados sintéticos simples, e não em problemas do mundo real, como o reconhecimento de imagens, que são mais complicados. “[Estamos] empurrando os limites lentamente”, diz Liu. “Interpretabilidade pode ser uma tarefa muito desafiadora.”
Ele e seus colegas também destacaram que as KANs se tornam mais precisas em suas tarefas à medida que aumentam de tamanho, e mais rapidamente do que os MLPs. A equipe provou o resultado na teoria e o demonstrou empiricamente empírico para demandas relacionadas à Ciência (como aprender a aproximar funções relevantes para a Física). “Ainda não está nítido se essa observação se estenderá a tarefas-padrão de Machine Learning, mas, pelo menos, para tarefas relacionadas à Ciência, parece promissora”, diz Liu.
O cientista reconhece que as KANs têm uma desvantagem importante: levam mais tempo e poder computacional para treinar em comparação a um MLP.
“Isso limita a eficiência da aplicação das KANs em conjuntos de dados de grande escala e tarefas complexas”, diz Di Zhang, da Universidade Jiaotong-Liverpool de Xi’an, na China. Apesar disso, ele sugere que algoritmos mais eficientes e aceleradores de hardware podem ajudar.
—


