
Na noite de quarta-feira, 2 de dezembro, Timnit Gebru, colíder da equipe de ética em Inteligência Artificial do Google, anunciou via Twitter que a empresa a havia demitido.
Gebru, uma líder amplamente respeitada no campo de pesquisas sobre ética em IA, é conhecida por ser coautora de um artigo inovador que mostrou que o reconhecimento facial é menos preciso na identificação de mulheres e pessoas negras, o que significa que seu uso pode acabar discriminando esses grupos. Ela também participou da fundação do grupo de afinidade Black in AI e defende a diversidade na indústria de tecnologia. A equipe que ela ajudou a construir no Google, é uma das mais diversas em IA e inclui muitos líderes especialistas por conta própria. Colegas de campo invejavam esse formato, por produzir um trabalho crítico que muitas vezes desafiava as práticas convencionais de IA.
Uma série de tweets, e-mails vazados e artigos da mídia mostraram que a saída de Gebru foi consequência de um conflito por outro artigo, de sua coautoria. Jeff Dean, chefe de IA do Google, disse aos colegas em um e-mail interno (que depois publicou online) que o artigo “não atendeu ao nosso padrão de publicação” e que Gebru disse que se demitiria a menos que o Google aceitasse algumas condições, com as quais a empresa não concordou. Pelo Twitter, Gebru disse que pediu para negociar “um último encontro” por sua posição, depois que ela voltasse das férias. Ela foi banida de seu e-mail corporativo antes de retornar.
Online, muitos outros líderes no campo da ética da IA estão argumentando que a empresa forçou sua saída, por causa das verdades inconvenientes que ela estava expondo sobre uma linha central de sua pesquisa – e possivelmente, seu resultado final. Mais de 1.400 funcionários do Google e 1.900 outros apoiadores também assinaram uma carta de protesto.
Muitos detalhes da sequência exata de eventos que levaram à partida de Gebru ainda não estão claros; tanto ela quanto o Google se recusaram a comentar além de suas postagens nas redes sociais. Mas a MIT Technology Review obteve uma cópia do artigo de pesquisa de uma das coautoras, Emily M. Bender, professora de linguística computacional da Universidade de Washington. Embora Bender tenha nos pedido para não publicar o artigo porque os autores não queriam um rascunho tão antigo circulando online, ele dá algumas dicas sobre as questões que Gebru e seus colegas estavam levantando sobre IA, que podem estar causando preocupação ao Google.
“On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” expõe os riscos de grandes modelos de linguagem – Inteligências Artificiais treinadas com enormes quantidades de dados de texto, que têm se tornado cada vez mais populares – e cada vez maiores – nos últimos três anos. Elas agora são extraordinariamente boas, nas condições certas, em produzir o que parece ser um novo texto convincente e significativo – e às vezes em estimar o significado da linguagem. Mas, diz a introdução do artigo, “questionamos se foram levados em consideração os riscos potenciais associados ao seu desenvolvimento e as estratégias para mitigar esses riscos”.
O artigo
O texto, que se baseia no trabalho de outros pesquisadores, apresenta a história do processamento de linguagem natural, uma visão geral dos quatro principais riscos dos grandes modelos de linguagem e sugestões para pesquisas futuras. Como o conflito com o Google parece ser sobre os riscos, nos concentramos em resumi-los aqui.
Custos ambientais e financeiros
O treinamento de grandes modelos de IA consome muito poder de processamento do computador e, portanto, muita eletricidade. Gebru e seus coautores referem-se a um artigo de 2019, de Emma Strubell e seus colaboradores, sobre as emissões de carbono e os custos financeiros de grandes modelos de linguagem. Descobriu-se que seu consumo de energia e pegada de carbono têm explodido desde 2017, à medida que os modelos são alimentados com mais e mais dados.
Benchmarks comuns de pegada de carbono
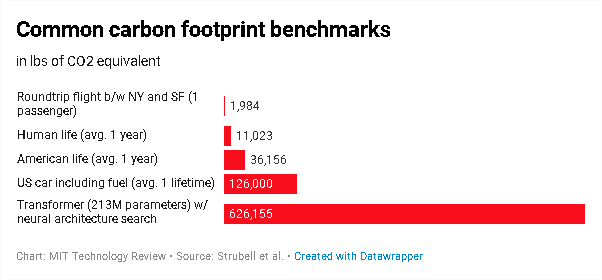
O estudo de Strubell descobriu que treinar um modelo de linguagem com um tipo específico de método de “pesquisa de arquitetura neural” (NAS) teria produzido o equivalente a 626.155 libras (284 toneladas métricas) de dióxido de carbono – aproximadamente a produção vitalícia de cinco carros americanos médios. Treinar uma versão do modelo de linguagem do Google, BERT, que sustenta o mecanismo de busca da empresa, produziu 1.438 libras de CO2, equivalente na estimativa de Strubell – quase o mesmo que um voo de ida e volta entre Nova York e São Francisco. Esses números devem ser vistos como mínimos, o custo de treinar um modelo uma única vez. Na prática, os modelos são treinados e retreinados várias vezes durante a pesquisa e o desenvolvimento.
The estimated costs of training a model once
In practice, models are usually trained many times during research and development.
| Date of original paper | Energy consumption (kWh) | Carbon footprint (lbs of CO2e) | Cloud compute cost (USD) | |
|---|---|---|---|---|
| Transformer (65M parameters) | Jun, 2017 | 27 | 26 | $41-$140 |
| Transformer (213M parameters) | Jun, 2017 | 201 | 192 | $289-$981 |
| ELMo | Feb, 2018 | 275 | 262 | $433-$1,472 |
| BERT (110M parameters) | Oct, 2018 | 1,507 | 1,438 | $3,751-$12,571 |
| Transformer (213M parameters) w/ neural architecture search | Jan, 2019 | 656,347 | 626,155 | $942,973-$3,201,722 |
| GPT-2 | Feb, 2019 | – | – | $12,902-$43,008 |
![]()
O rascunho do documento de Gebru aponta que os recursos absolutos necessários para construir e manter tais modelos de IA significam que eles tendem a beneficiar organizações ricas, enquanto as mudanças climáticas atingem com mais força as comunidades marginalizadas. “Já passou da hora de os pesquisadores priorizarem a eficiência energética e os custos para reduzir o impacto ambiental negativo e o acesso desigual aos recursos”, escrevem eles.
Dados massivos, modelos inescrutáveis
Modelos de grande linguagem também são treinados em quantidades de texto exponencialmente crescentes. Isso significa que os pesquisadores buscam coletar todos os dados que podem da Internet, então há o risco de que linguagem racista, sexista ou abusiva acabe nos dados de treinamento.
Um modelo de IA ensinado a ver a linguagem racista como normal é obviamente ruim. Os pesquisadores, porém, apontam alguns problemas mais sutis. Um é que as mudanças na linguagem desempenham um papel importante na mudança social; os movimentos MeToo e Black Lives Matter, por exemplo, tentaram estabelecer um novo vocabulário antissexista e antirracista. Um modelo de IA treinado em vastas áreas da internet não estará sintonizado com as nuances deste vocabulário e não produzirá ou interpretará a linguagem de acordo com essas novas normas culturais.
Também não conseguirá capturar o idioma e as normas de países e povos que têm menos acesso à Internet e, portanto, imprimem uma pegada linguística menor online. O resultado é que a linguagem gerada pela IA será homogeneizada, refletindo as práticas dos países e comunidades mais ricos.
Além disso, como os conjuntos de dados de treinamento são tão grandes, é difícil auditá-los para verificar esses vieses incorporados. “Uma metodologia que depende de conjuntos de dados muito grandes para documentar é, portanto, inerentemente arriscada”, concluem os pesquisadores. "Embora a documentação permita uma maior responsabilização, [...] os dados de treinamento não documentados perpetuam os danos sem recurso."
Custos de oportunidade de pesquisa
Os pesquisadores resumem o terceiro desafio como o risco de "esforço de pesquisa mal direcionado". Embora a maioria dos pesquisadores de IA reconheça que grandes modelos de linguagem não entendem realmente a linguagem e são meramente excelentes em manipulá-la, Big Techs podem ganhar dinheiro com modelos que manipulam a linguagem com mais precisão, por isso continuam investindo neles. “Este esforço de pesquisa traz consigo um custo de oportunidade”, escrevem Gebru e seus colegas. Não é necessário muito esforço para trabalhar em modelos de IA que possam alcançar a compreensão ou que alcancem bons resultados com conjuntos de dados menores e mais cuidadosamente selecionados (e, portanto, também usem menos energia).
Ilusões de significado
O problema final com grandes modelos de linguagem, segundo os pesquisadores, é que, por serem tão bons em imitar a linguagem humana real, é fácil usá-los para enganar pessoas. Houve alguns casos de grande destaque, como o de um estudante universitário que lançou conteúdo de autoajuda gerada por IA e conselhos de produtividade em um blog, que se tornou viral.
Os perigos são óbvios: os modelos de IA poderiam ser usados para gerar desinformação sobre uma eleição ou a pandemia covid-19, por exemplo. Eles também podem dar errado desapercebidamente, quando usados para tradução automática. Os pesquisadores citam um exemplo: em 2017, o Facebook traduziu incorretamente a postagem de um homem palestino, que dizia "bom dia" em árabe, como "ataque-os" em hebraico, levando à sua prisão.
Por que isso importa
O artigo de Gebru e Bender tem seis coautores, quatro dos quais são pesquisadores do Google. Bender pediu para evitar revelar seus nomes por medo de repercussões. (Bender, ao contrário, é uma professora titular: “Acho que isso está enfatizando o valor da liberdade acadêmica”, diz ela.)
O objetivo do artigo, diz Bender, era fazer um balanço do panorama da pesquisa atual em processamento de linguagem natural. “Estamos trabalhando em uma escala em que as pessoas que estão construindo as coisas não podem realmente controlar os dados”, disse ela. “E porque as vantagens são tão óbvias, é particularmente importante dar um passo atrás e nos perguntar, quais são as possíveis desvantagens? … Como obtemos os benefícios disso, ao mesmo tempo que mitigamos o risco? ”
Em seu e-mail interno, Dean, o chefe de IA do Google, disse que um dos motivos pelos quais o artigo "não atendeu ao nosso padrão" foi que "ignorou muitas pesquisas relevantes". Especificamente, ele disse que não mencionou o trabalho mais recente sobre como tornar grandes modelos de linguagem mais eficientes em termos de energia e mitigar problemas de preconceito.
No entanto, os seis colaboradores contaram com uma ampla gama de estudos. A lista de citações do artigo, com 128 referências, é notavelmente longa. “É o tipo de trabalho que nenhum indivíduo ou mesmo dupla de autores pode realizar”, disse Bender. “Realmente exigiu esta colaboração.”
A versão do artigo que vimos também acata vários esforços de pesquisa sobre a redução do tamanho e os custos computacionais de grandes modelos de linguagem e sobre a medição do viés embutido dos modelos. Ela argumenta, porém, que esses esforços não foram suficientes. “Estou muito aberta para ver quais outras referências devemos incluir”, disse Bender.
Nicolas Le Roux, um pesquisador de IA do Google no escritório de Montreal, observou mais tarde no Twitter que o raciocínio no e-mail de Dean era incomum. “Minhas submissões sempre foram verificadas quanto à divulgação de material sensível, nunca pela qualidade da literatura”, disse ele.
Now might be a good time to remind everyone that the easiest way to discriminate is to make stringent rules, then to decide when and for whom to enforce them.
My submissions were always checked for disclosure of sensitive material, never for the quality of the literature review.— Nicolas Le Roux (@le_roux_nicolas) December 3, 2020
O e-mail de Dean também diz que Gebru e seus colegas deram ao Google AI apenas um dia para uma revisão interna do artigo antes de enviá-lo para uma conferência, para publicação. Ele escreveu que “nosso objetivo é rivalizar com os artigos de competidores, em termos de rigor e consideração na forma como revisamos a pesquisa antes da publicação”.
I understand the concern over Timnit’s resignation from Google. She’s done a great deal to move the field forward with her research. I wanted to share the email I sent to Google Research and some thoughts on our research process.https://t.co/djUGdYwNMb
— Jeff Dean (@🏡) (@JeffDean) December 4, 2020
Bender observou que, mesmo assim, a conferência ainda colocaria o artigo em um processo de revisão substancial: “É sempre uma conversa e sempre um trabalho em andamento”, disse ela.
Outros, incluindo William Fitzgerald, um ex-gerente de RP do Google, lançaram dúvidas sobre a afirmação de Dean:
This is such a lie. It was part of my job on the Google PR team to review these papers. Typically we got so many we didn't review them in time or a researcher would just publish & we wouldn't know until afterwards. We NEVER punished people for not doing proper process. https://t.co/hNE7SOWSLS pic.twitter.com/Ic30sVgwtn
— William Fitzgerald (@william_fitz) December 4, 2020
O Google foi o pioneiro em grande parte da pesquisa fundamental que desde então levou à recente explosão de grandes modelos de linguagem. O Google AI foi o primeiro a inventar o modelo de linguagem Transformer em 2017, que serve como base para o modelo posterior da empresa, BERT, e GPT-2 e GPT-3 da OpenAI. BERT, como observado acima, agora também impulsiona o buscador do Google, a fonte de renda da empresa.
Bender teme que as ações do Google possam criar "um efeito assustador" nas pesquisas futuras sobre ética em IA. Muitos dos maiores especialistas em ética em IA trabalham em grandes empresas de tecnologia porque é onde que está o dinheiro. “Isso tem sido benéfico de várias maneiras”, diz ela. “Mas acabamos com um ecossistema que talvez tenha incentivos que não são os melhores para o progresso da ciência para o mundo.”


