
Um bom marco inicial para esta história é o ano de 1940, quando foi desenvolvido o primeiro computador por Alan Turing – ou algo bem próximo do computador. Ele teve um papel importante no fim da Segunda Guerra Mundial ao decifrar os códigos alemães da máquina Enigma. Curioso é que o próprio criador da máquina já filosofava em 1950 sobre a habilidade dessa máquina se tornar humana propondo o Teste de Turing – se algum dia uma máquina enganasse um humano numa conversa de chat, ela seria inteligente.
No entanto, não foi Turing que cunhou o termo Inteligência Artificial e sim John McCarthy, em 1956, durante a Conferência de Dartmouth, nos Estados Unidos. McCarthy usou o termo “Inteligência Artificial” para descrever o campo emergente de estudo da computação que se concentrava em fazer com que as máquinas pudessem imitar a capacidade humana de raciocinar, aprender e resolver problemas. O objetivo dele era diferenciar esta linha de pesquisa da psicologia e da neurociência.
Evolução tecnológica
A Inteligência Artificial, então, trata-se originalmente de uma inteligência de chat (conversação em inglês). Apesar de ter perdido a sua essência ao longo do tempo devido a falta de bons resultados é importante lembrar a sua missão original.
O processamento de textos por computadores sempre foi um problema complexo porque exige da matemática um ambiente super dimensional, com muitas dimensões, quase infinitas, que seriam representadas por cada palavra da língua.
Por falta de resultados satisfatórios, os investimentos foram enxugados e a área acabou se juntando a outras mais quantitativas e de resultados mais imediatos. Por isso a mistura entre Inteligência Artificial e aprendizado de máquina até hoje.
Voltando às origens, o ChatGPT é um robô de conversação (chat) que utiliza algoritmos do campo da PLN, Processamento da Linguagem Natural, (NLP em inglês) para responder perguntas dos usuários. E foi sim, um dos primeiros a adentrar na área de texto com certa eficiência, então por isso seus resultados fizeram uma verdadeira revolução na área de Inteligência Artificial.
Porém, esta tecnologia não surgiu do nada. O Google, sempre pioneiro, teve sim papel relevante nessa evolução. Desde os anos 2000, seus algoritmos avançaram muito o campo de processamento de textos por computador. A empresa desenvolveu o Hadoop, um sistema de processamento de máquina distribuído que trouxe uma capacidade de processar terabytes de informações e deu início à explosão do Big Data. Como veremos, fator crucial para atingir os resultados do GPT.
Computação Visual
Antes da área de texto, a computação visual já vinha mostrando resultados na área de Inteligência Artificial. O algoritmo de Deep Learning, co-criado por Andrew Ng trabalhando na Universidade de Stanford, para o Google, já apresentava bom potencial para lidar com imagens. Para provar isso, era necessário bases de dados para treinamento.
Foi então que, em 2010, surgiu o Desafio ImageNet que compreendia uma base de milhões de imagens catalogadas e rotuladas de acordo com o que continha nelas. Era a oportunidade perfeita para mostrar as capacidades de treinamento do Deep Learning.
Utilizando as potentes placas gráficas da computação visual (GPUs), em 2012, o algoritmo desafiador batizado de AlexNet ganhou o torneio com 85% de acerto, atingindo pontuações próximas ao nível humano. Era uma questão de tempo para ele ultrapassar.
Em mais detalhes, o algoritmo utilizado foi a rede neural Convolutional Neural Network (CNN), uma tecnologia de Deep Learning capaz de processar os dados em camadas capturando estruturas primitivas de contexto e estimando ao final a classificação de maior probabilidade com a função Softmax.
Processamento de Textos
Enquanto as imagens atingiam resultados, em uma outra linha do tempo, o Google avançava no processamento computacional de textos, a principal área dele, e lançou em 2013 o modelo Word2Vec. A técnica foi criada por uma equipe de pesquisadores liderada por Tomas Mikolove apresentada pela primeira vez em um artigo científico intitulado “Efficient Estimation of Word Representations in Vector Space”. O artigo descreve uma forma eficiente de representar palavras em vetores matemáticos representados pelas palavras próximas a ela no texto, formando um contexto. Através do cálculo da distância destes vetores, os computadores poderiam estimar a similaridade semântica entre as duas palavras.
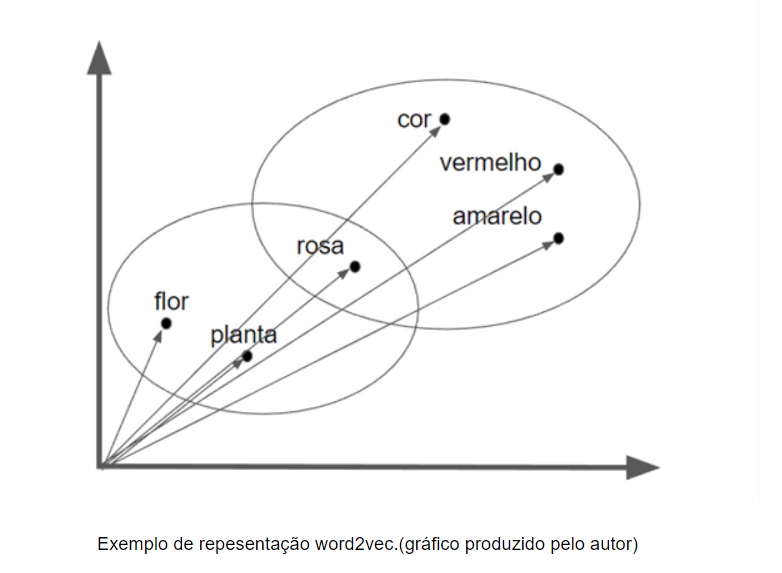
O grande desafio dos modelos em linguagem natural sempre foi tentar encontrar o significado das palavras, ou melhor, uma forma de separar um significado de outro. As palavras em linguagem natural, como o português por exemplo, são dotadas de muita ambiguidade, ou seja, a mesma palavra tem significados diferentes em diferentes contextos. Sendo assim, o computador deveria ser capaz de desambiguizar as palavras através do contexto em que elas se inseriram. Este contexto seria representado pelas palavras que apareciam em volta ou próximas, e ao vetor seria dado o nome de SemanticVector. Então, o Word2Vec se tornou uma ótima arquitetura para trabalhar com estes vetores semânticos.
Depois que o algoritmo Word2Vec foi inserido na biblioteca de código aberto do TensorFlow ele se tornou amplamente popular e publicações em textos começaram a avançar mundo afora.
Processamento da Linguagem Natural
A diferença do Processamento da Linguagem Natural (PLN) para o processamento de textos é a importância da ordem na escrita. Os exemplos “O cachorro mordeu o menino” é completamente diferente de “O menino mordeu o cachorro”, apesar de as palavras estarem próximas do mesmo jeito. Um novo modelo que levasse a ordem das palavras em consideração era necessário.
Até chegarem os Transformers, o modelo mais utilizado para capturar a ordem eram as Redes Neurais Recorrentes (RNN em inglês, 2014, https://arxiv.org/abs/1409.0473). Essa abordagem processava não só uma palavra, mas uma sequência inteira, o que permitia guardar melhor o contexto. Seu sucesso se deu principalmente nas tarefas de tradução de textos de uma língua para outra. Bases gigantes de textos traduzidos e alinhados podiam trocar massivamente trechos de texto de uma língua para outra produzindo um bom acerto. O método era bom em pequenos trechos, mas grandes parágrafos poderiam estourar a capacidade de memória do computador.
Uma melhoria foi introduzida em 2015 com o conceito de Attention. Este método era, na verdade, um filtro que incluía trabalhos de linguistas em classificação gramatical anotada. Esse filtro podia diminuir bastante a complexidade do problema ao descartar palavras com menos importância e processava apenas as palavras com mais significado, como os substantivos por exemplo.
Mesmo assim, as RNN ainda davam muito trabalho ao demandar muita memória com as sequências ao invés de palavras. Isso impedia o algoritmo de poder processar um volume grande de texto. E sabemos que a inteligência ou a mágica da inteligência está justamente no volume de dados. Quanto maior a base, mais assustados ficamos com o resultado.
O encontro das áreas
Era a hora de grupos das diferentes áreas da computação sentarem para conversar, os eficientes algoritmos da imagem junto com os contextos de linguagem. Em 2017 isso aconteceu e adaptaram a ImageNet para o PLN, surgindo a técnica de Transformer, primeiramente citada no paper “Attention is All You Need Paper” (https://arxiv.org/pdf/1706.03762.pdf)
A evolução veio na forma de gerar os dados, enquanto as RNN criavam um novo token com a frase inteira, a Transformer quebrava ela toda em pequenas partes e anexava um número representando a sua posição na sequência. Indicando a ordem. Assim como o Word2Vec transformou as palavras em números, a técnica Transformer transformou a sintaxe em número.
Os computadores são ótimos em números, e a ordem das palavras estava representada também nos vetores, o treinamento pode ser novamente paralelizado, distribuído e escalado com a utilização das placas de vídeo GPU. Terabytes à espera de treinamento.
Os primeiros resultados vieram para bases de código de computador, linguagens de programação, pois como está na raiz do algoritmo, alinhar sequências de linguagem sem muita ambiguidade é o que ele faz de melhor.
Google, BERT e GPT
O Google, então, aproveitou os resultados do encontro das áreas e lançou, em 2018 o modelo BERT, Bidirectional Encoder Representations from Transformers (https://arxiv.org/abs/1810.04805). O BERT usou apenas a base da Wikipedia para aprender as palavras e sentenças, mas já se tornou o modelo líder no mercado em uma série de tarefas de PLN.
Em 2019, o GPT-2 foi lançado como uma extensão do BERT. Enquanto o BERT foi pré-treinado em tarefas de preenchimento de lacunas e previsão de sentenças, o GPT-2 foi pré-treinado em uma tarefa de previsão de palavras, ou seja, dada uma palavra ou sequência de palavras, o modelo tenta prever a próxima palavra na sequência. Isso levou a uma melhor compreensão da relação entre palavras e sentenças e permitiu que o modelo produzisse texto de alta qualidade gerado pelo computador.
Visto o impacto do resultado do GPT-3, voltaram os investimentos nos centros de IA e novas versões começaram a aparecer como RoBERTa do Facebook, ERNIE 2.0 da Baidu e mais recentemente o Bard, do próprio Google.
A história da OpenAI
Sam Altman, cofundador da OpenAI, era presidente da conhecida aceleradora dos Estados Unidos, Y-Combinator. Ele foi o primeiro investidor da empresa quando viu o seu projeto passando pela incubadora colocando U$1 milhão em 2015 na sua fundação.
O primeiro produto da OpenAI foi focado na área de videogames. Em 2016, algoritmos de Reinforcement Learning eram usados para treinar agentes dentro de um ecossistema virtual de punição e recompensa. Os agentes criavam estratégias de jogo, testavam e o algoritmo acabava decidindo qual era o melhor.
Apesar de Elon Musk ter sido um dos investidores da empresa – dentre vários – ele saiu antes mesmo do lançamento do sucesso DALL-E, o primeiro modelo generativo para imagens. A justificativa foi que havia conflitos de interesse com o desenvolvimento da Inteligência Artificial da Tesla.
Enquanto o DALL-E fazia sucesso, a empresa já fazia seu próprio modelo generativo para textos, o GPT, treinado com 7000 livros. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
O resultado foi animador e a Microsoft fez o primeiro aporte de U$1 bilhão. Em 2019, influenciado pelo BERT ou não, veio o GPT-2 com um banco de dados de treinamento de 8 milhões de páginas da Web contendo 1,5 bilhões de anotações gramaticais.
Com isso eles conseguiram fazer um sistema tão bom de completar textos e em suas variantes que eles diziam que completava seus pensamentos e respondia perguntas. O valor era latente e eles decidiram não abrir mais o código ao público. Nada mais de “Open”AI. A desculpa foi que esta inteligência era muito poderosa e poderia ser usada para o mal. De fato, o ChatGPT vem cheio de políticas de restrição de conteúdo para não cair em polêmicas.
De código fechado, o GPT-3, ainda mais avançado, foi lançado em 2020. O modelo foi capaz de produzir texto quase indistinguível do texto humano. https://arxiv.org/pdf/2005.14165.pdf
Em 2022, a OpenAI entrega o GPT-3.5, agora com pré-treinamento de 45TB em texto. Para isso a Microsoft disponibilizou o quinto melhor computador do mundo com milhares de CPUs e GPUs para conseguir processar tudo. Em novembro de 2022, é lançado ao público o produto ChatGPT com resultados que nos surpreendem até hoje. Para muitos, o primeiro contato real com uma IA. O impacto foi tão grande que, em janeiro de 2023, a Microsoft decidiu comprar a empresa com um novo aporte de U$10 bilhões.
E o futuro…
Apesar do Google ser ainda o grande favorito na corrida de chats, PLN e IA, dominando o mercado de buscas de textos há décadas, a Microsoft deu um grande primeiro passo nesta direção. Uma das grandes vantagens de ser o primeiro a ter uma IA como o ChatGPT disponível de graça, é que seu maior uso trará mais correções e com isso maior aprendizado para a próxima versão.
Além disso, se mais dados, nesse caso, geraram melhores resultados, a próxima versão ChatGPT-4 virá com um significativo incremento na base de treinamento.
No longo prazo o Google está lançando a sua versão, o Bard, um concorrente que pode trazer informações atualizadas acoplado ao seu mecanismo de buscas que tem 90% de penetração do mercado. Em breve saberemos em que mão estará o futuro da IA.
Por um ou por outro, a IA já está em nossas vidas, e este artigo já foi escrito com interações supervisionadas usando o próprio ChatGPT.
Este artigo foi produzido por Christian Aranha, Empreendedor e pesquisador na área de Inteligência Artificial, Big Data e Blockchain, autor do livro Bitcoin, Blockchain e Muito Dinheiro e colunista da MIT Technology Review Brasil.

